理解真实项目中的 Go 并发 Bug
时间:2021-9-8 作者:smarteng 分类: Go语言
本文内容源于论文《Understanding Real-World Concurrency Bugs in Go》,从 6 个非常流行的开源项目中,收集了 171 个并发 bug,从传统的共享内存访问、Go 语言新的并发原语的特性方面入手,研究了并发 bug 产生的原因以及修复的方法,以便使 Go 研发人员更好的理解 Go 并发模型以及使用 Go 语言编写出更稳定、健壮的软件系统。

表 1 中列出了选择的 6 个开源项目包括数据中心容器系统(Docker、Kubernetes)、分布式 key-value 存储系统(etcd)、数据库系统(CockroachDB、BoltDB)和 gRPC。从星级(starts)看都是流行的开源项目。研发的年份至少 3 年以上。项目规模从几千行代码到百万行代码不等。 可以看出,选择的项目非常具有代表性。
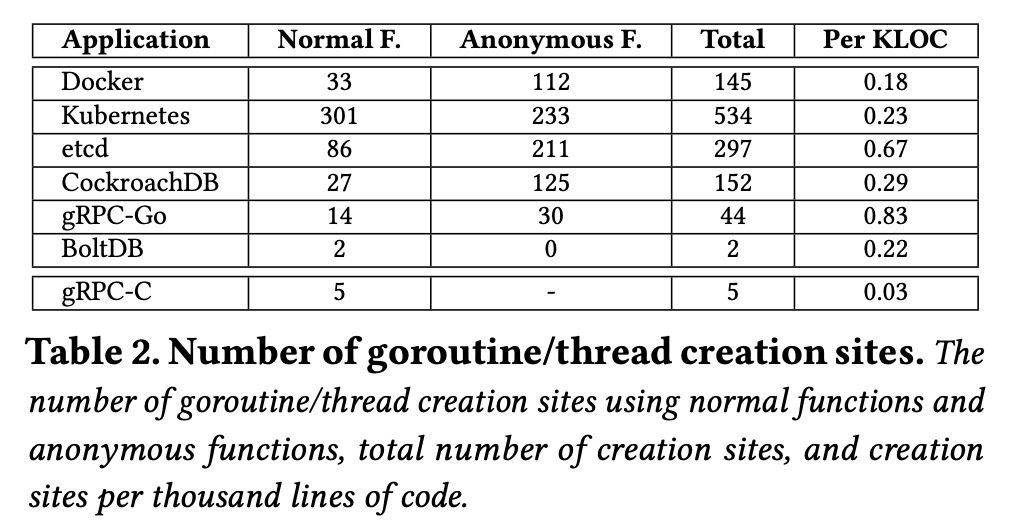
表 2 表明各项目中都大量的使用了协程。和最后一行的 gRPC-C(用 C 语言实现的)线程相比可知,gRPC-C 的每千行代码平均创建 0.03 个线程,而用 Go 实现的项目,平均从千行代码平均 0.18 个协程,到 0.83 个协程。

表 4 中显示的是各项目使用的并发原语的占比统计。其中传统的共享内存访问中主要集中在 Mutex 原语上,而消息传递原语的使用则主要集中在 Channel 的使用上。由此可以看出,Go 虽然推荐在协程之间 “使用通信来共享内存,而不是通过共享内存来通信”,但由该表可知,Go 同时支持共享内存和通道通信两种并发模式。而且,在实际项目中,使用共享内存相关原语还多于通道通信的并发模式。
该研究基于这 6 个开源项目,共收集了 171 个并发 bug,并将这 171 个并发 bug 分为两个维度:引起 bug 的原因和 bug 的表现行为(阻塞 bug 和非阻塞 bug)。
阻塞 bug

表格 6 显示了阻塞 bug 的原因统计。根据该表显示,在收集到的 82 个 bug 中共计 36 个 bug 是因为对共享内存访问的保护错误导致的,有 46 个是因为误用消息传递导致的。
- 对共享内存访问导致的 bug 进一步细化分析:
- 有 28 个是因为 Mutex 的使用不正确,包括重复获取锁,获取锁的顺序存在冲突,忘记释放锁等操作。
- 5 个在 RWMutex 上。在 Go 中写锁比读锁有更高的优先级。如果一个协程 A 先执行一次读锁即 sync.RWMutex.RLock(),然后一个协程 B 进行获取写锁操作 sync.RWMutex.Lock(),然后协程 A 再进行获取读锁操作,sync.RWMutex.RLock()。 这样就会形成一个死锁。因为 A 第一读锁可以获取成功,然后协程 B 获取写锁时,会被阻塞。然后协程 A 再次获取读锁时,也会被 B 的写锁堵塞住。
- 3 个在 Wait 上。一般是一个进程使用了 Cond.Wait(),但没有其他协程调用 Cond.Signal() 来解除等待。
- 对消息传递导致的 bug 进一步细化分析:
- 有 29 个是因为误用 Channel。一般和通道相关的阻塞 bug 是因为没有向通道发送消息(或从通道接收消息)或关闭通道,而导致正在等待从通道接收消息(或等待往通道发送消息)的协程阻塞。
- 有 16 个 bug 是因为通道和其他阻塞原语一起使用造成的。比如一个协程因为通道阻塞,另一个协程因为锁或 wait 操作阻塞。
- 有 4 个 bug 是因为误用 Go 中的消息库造成的。
根据以上的阻塞 bug 的原因,那么对应的修复 bug 的方法一般如下:
- 通过添加缺少的解锁操作
- 移动 lock 或 unlock 操作到合适的未知
- 移除多余的锁操作
- 在 select 语句中增加 default 分支或在一个不同通道上的 case 操作
- 将 unbuffered channel 替换成 buffered chanel
如图表 7 中,展示了对阻塞 bug 的修复策略的总结。从对并发原语的添加、移动位置、改变、移除或混合使用共享内存和消息通讯的并发原语来解决阻塞的并发 bug。
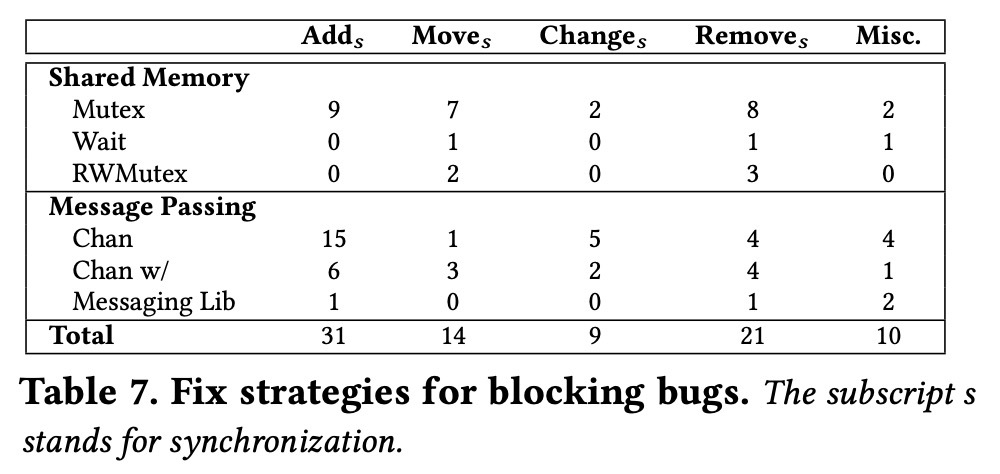
由此可见,在该研究中(传统的共享内存的方式和消息传递的方式)的大部分阻塞 bug 都可以通过简单的方案修复,并且很多修复都是跟 bug 引起原因相关的。
也就是说,阻塞 bug 引起的原因一般是由对共享内存的原语和消息传递到原语使用不当造成的。同时在 Go 中,错误的使用消息传递的方式导致的阻塞 bug 多余错误的使用共享内存原语,高达 58%。然而在解决阻塞 bug 时的方法也很简单,一般通过移动、删除、添加对应解锁原语即可解决。
非阻塞 bug
非阻塞 bug 一般是表现为协程之间产生数据竞争,而引起数据竞争的主要原因还是因为没有对共享内存进行保护或错误的保护了共享内存访问。
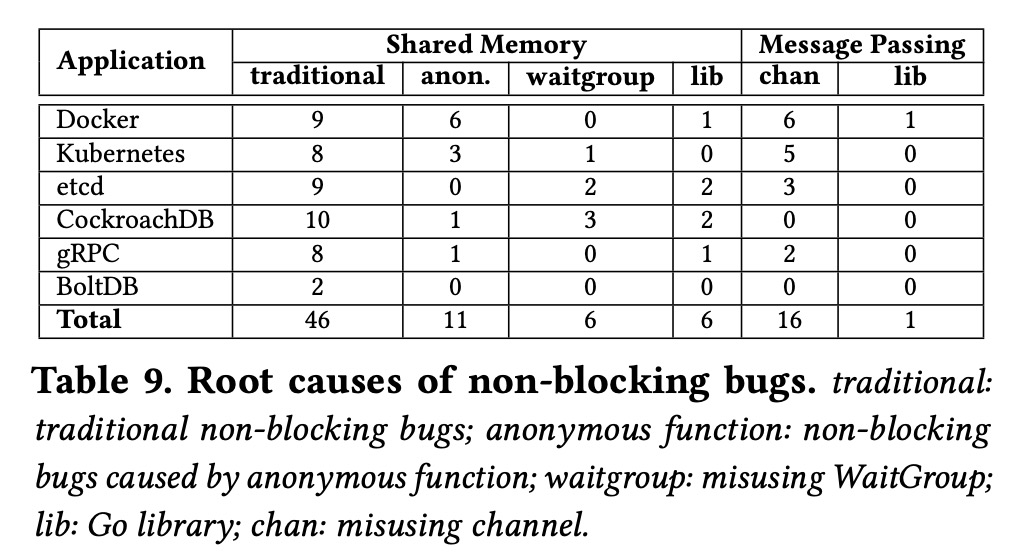
表 9 统计了非阻塞 bug 引起的原因。在收集的 bug 中,大概有 80% 的是因为没有保护共享内存访问或保护错误。
- 对共享内存访问导致的 bug 进一步细化分析:
- 传统的 bug:大部分是因为类似原子性,顺序冲突或数据竞争造成的。
- 匿名函数:在 Go 中可以通过匿名函数来启动协程,这样匿名函数就可以访问本地的变量,如果使用不当,就加大了数据竞争的机会。
- 误用 WaitGroup。这是 Go 中的新特性,由于对 WaitGroup 使用的理解不足,造成在调用 Wait 和 Add 的时候顺序不一致,造成非阻塞 bug。
- 对 Go 提供的库函数理解不足。Go 中提供了很多库函数,这些库函数可能会隐式的存在变量共享,如果使用不正确,则会非常容易造成非阻塞 bug。
- 对消息传递导致的 bug 进一步细化分析
- 误用通道: 在 Go 中使用通道需要遵循一些基本原则,比如通道只能关闭一次,select 的 case 语句中都准备好时,是随机选择 case 分支的
- Go 中提供的特殊库的使用:Go 中有些库使用了通道,研发人员在使用该库时如果对其内部不了解,也容易因为误用而造成非阻塞 bug。
针对以上问题,我们看下对非阻塞 bug 的修复策略,如表 10 所示。
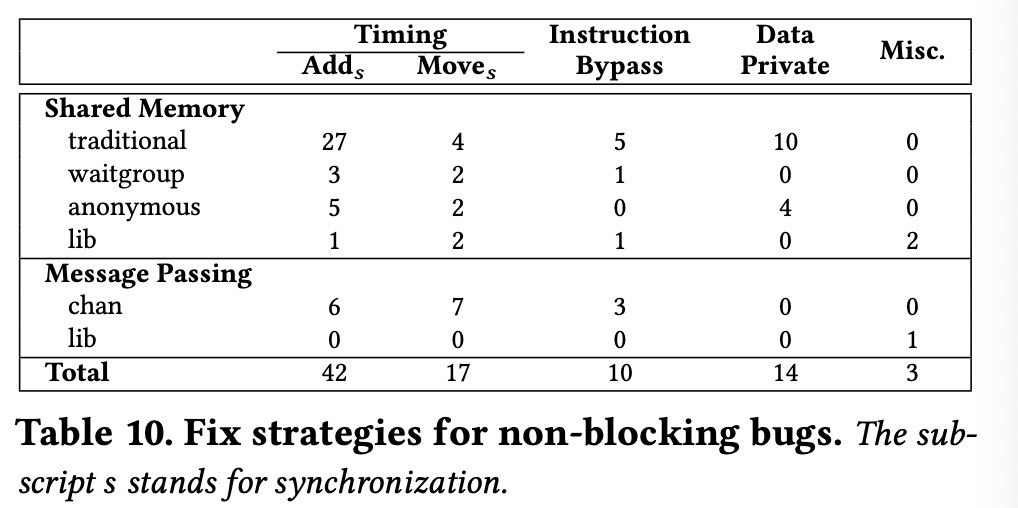
表 10 展示了非阻塞 bug 的修复策略。根据表 10 可知:
- 69% 的非阻塞 bug 可以通过严格的时间顺序进行修复,或者通过增加像 Mutex 这样的同步原语,或移动已有的同步原语到合适的未知,类似于 Add。
- 通过对共享变量进行私有化
- 通过移除共享变量访问的指令。
并发 Bug 示例展示
- 示例 1:该示例节选自 Docker 项目,是由 WaitGroup 引起的阻塞 Bug。
1 var group sync.WaitGroup 2 group.Add(len(pm.plugins)) 3 for _, p := range pm.plugins { 4 go func(p *plugin) { 5 defer group.Done() 6 } 7 - group.Wait() 8 } 9 +group.Wait()该示例中的 bug 是因为 WaitGroup 类型的共享变量 group 引起的。因为在第 2 行,len(pm.plugins) 被用做了 Add 的参数,所有只有当第 5 行的 group.Done() 被调用 len(pm.plugins) 次时,第 7 行的 group.Wait() 才会被解除阻塞。因为 Wait 的调用放在了 for 循环的内部,所以,它会阻塞 for 循环在第 4 行后续的协程的创建,并且也阻塞了每个被创建协程的 Done 函数的调用。那么修复方法就是将 Wait 方法移动到 for 循环外,如示例中的第 9 行。
- 示例 2:由 channel 和 lock 的错误使用导致的阻塞 bug
1 func goroutine1() { 2 m.Lock() 3 ch <- request //blocks 4 select { 5 case ch <- request 6 default: 7 } 8 m.Unlock() 9 } 10 func goroutine2() { 11 for { 12 m.Lock() //blocks 13 m.Unlock() 14 request <- ch 15 } 16 }该示例中,goroutine1 和 goroutine2 两个协程,同时共享父协程的非缓冲通道 ch。因为在第 3 中的 ch 输入,只有在第 14 行 goroutine2 从 ch 读取 request 之后才能写入成功,所以 goroutine1 在第 3 行将 request 发送到 channel 中时被阻塞,同时第 12 行 goroutine2 在 m.Lock() 的位置被阻塞,因为第 2 行 goroutine1 中已经进行了 m.Lock()。所以就造成了死锁。修复办法就是将第 3 行去掉,增加 4-7 行的 select-case-default 分支。
- 示例 3:由匿名函数引起的数据竞争的非阻塞 bug,该 bug 也是来源于 Docker 项目
1 for i := 17; i <= 21; i++ {// write 2- go func() { /*Create a new goroutine*/ 3+ go func(i int) { 4 apiVersion := fmt.Sprintf("v1.%d", i) //read 5 ... 6- }() 7+ }(i) 8}父进程和第 2 行的子协程共享变量 i,研发者的意图是每个子协程都用不同的 i 值初始化 apiVersion 变量。然而,在这个程序中 apiVersion 的值是不确定的。这跟 go 中子协程的调度时机有关系。例如,子协程开始执行的时间是在整个 for 循环之后,那么 apiVersion 值就会是"v1.21"。只有当每个子协程在创建字符串 apiVersion 变量之后且在变量 i 被分配新值之前就立即初始化 apiVersion 变量,那么该程序才能得到期望的结果。Docker 研发者就通过每次创建协程的时候就拷贝一个 i 值来修复了此 bug。
- 示例 4:该示例展示了一个由 Timer 导致的非阻塞 bug
1 - timer := time.NewTimer(0) 2 + var timeout <-chan time.Time 3 if dur > 0 { 4 - timer = time.NewTimer(dur) 5 + timeout = time.NewTimer(dur).C 6 } 7 select { 8 - case <- timer.C: 9 + case <- timeout: 10 case <- ctx.Done() 11 return nil 12 }上面示例中,程序的意图是设计一个计时器。在第 1 行,创建了一个 timer 对象,超时时间是 0。在创建 Timer 对象的同时,Go 运行时环境就会隐式的开启一个内部的协程,以供倒计时用。在第 4 行 timer 的超时时间被设置为 dur。开发者意图是仅当 dur 大于 0 或当 ctx.Done() 的时候从当前函数中返回。然而,当 dur 小于等于 0 时,Go 运行时创建的倒计时的协程将会在 timer 创建的时候就会给 timer.C 通道发送信号量,在第 8 行导致函数过早的返回。
- 示例 5:该 bug 来自 etcd 项目,由于误用 WaitGroup 导致的非阻塞 bug
1 func(p *peer) send() { 2 p.mu.Lock() 3 defer p.mu.Unlock() 4 switch p.status { 5 case idle: 6 + p.wg.Add(1) 7 go func() { 8 - p.wg.Add(1) 9 ... 10 p.wg.Done() 11 }() 12 case stopped: 13 } 14 } 15 func (p *peer) stop() { 16 p.mu.Lock() 17 p.status = stopped 18 p.mu.Unlock() 19 p.wg.Wait() 20 }
该 bug 中,在第 8 行的 Add 函数不一定能够保证在第 19 行的 Wait 语句之前执行。修复方法是将第 8 行的 Wait 函数移动到第 6 行,这样就能保证 Add 函数一定能在 Wait 函数之前运行。

smarteng
人生就流星,虽然转瞬即逝,但也有永恒。
- 使用Erlang的OTP框架创建应用
- php 使用curl模拟登录discuz以及模拟发帖
- 腾讯QQ、阿里旺旺、淘宝、MSN在线状态代码生成
- 新浪微博错误代码解析
- erlang程序设计笔记
- 《HTML 5与CSS 3权威指南》权威的HTML5与CSS3实战教程
- dedecms修改数据库密码配置文件
- 服务器优化小记--Etag和Expires
- 在PHP5中使用PHPMailer发送邮件
- PHP中冒号、endif、endwhile、endfor介绍
- Mediawiki的配置和修改方法
- PHP框架——ThinkPHP
- QQ登陆成功返回openId后与网站绑定
- 使用Golang的官方mock工具--gomock、mockgen
- MacOs 电脑关闭/打开IPV6
- MacOs 电脑关闭/打开IPV6
- MySQL中datetime和timestamp的区别
- C++声明结构
- 如何保证数据库和缓存的一致性
- 优雅的golang日期时间处理库go-carbon
- API接口纪要
- 解析 Golang 测试(11)- 模糊测试
- 解析 Golang 测试(10)- 什么是好的单测
- 解析 Golang 测试(9)- 一篇文章搞懂 testify
- 解析 Golang 测试(8)- gomonkey 实战
- 解析 Golang 测试(7)- 如何针对 Redis 进行 Fake 测试
- 解析 Golang 测试(6)- 如何针对 MySQL 进行 Fake 测试
- 解析 Golang 测试(5)- MySQL 经典 mock driver—— sqlmock
- 解析 Golang 测试(4)- 一篇文章教你分清 Mock,Stub,Fake
- 解析 Golang 测试(3)- goconvey 实战
- 2023年11月(1)
- 2023年10月(1)
- 2023年3月(2)
- 2023年2月(1)
- 2022年12月(1)
- 2022年9月(13)
- 2022年8月(5)
- 2022年7月(9)
- 2022年6月(2)
- 2022年5月(2)
- 2022年4月(1)
- 2022年3月(2)
- 2021年12月(1)
- 2021年11月(14)
- 2021年10月(2)
- 2021年9月(111)
- 2015年3月(1)
- 2014年5月(4)
- 2014年4月(18)
- 2014年1月(1)
- 2013年11月(2)
- 2013年7月(1)
- 2013年6月(1)
- 2013年3月(13)
- 2013年2月(3)
- 2013年1月(1)
- 2012年12月(8)
- 2012年11月(8)
- 2012年10月(1)
- 2012年9月(13)
- 2012年8月(4)
- 2012年6月(2)
- 2012年5月(10)
- 2012年4月(13)
- 2012年3月(9)
- 2012年2月(8)
- 2011年11月(1)
- 2011年8月(9)
- 2011年7月(8)
- 2011年6月(8)
- 2011年5月(7)
- 2011年4月(19)
- 2011年3月(15)
- 2011年2月(8)
- 2011年1月(9)
- 2010年12月(2)
- 2010年11月(2)
- 2010年10月(2)
- 2010年9月(8)
- 2010年8月(9)
- 2010年7月(1)
- 2010年6月(9)
- 2010年5月(5)
- 2010年1月(7)
- 2009年12月(21)
- 2009年11月(29)
- 2009年10月(100)
- 2009年8月(1)
- 2009年7月(15)
- 2009年6月(52)